
前言
好久没写了,这几天都在忙活自瞄的事,记录一下吧
被amd rocm超晕
前几天都在打螺丝,没什么好说的,回家后没有显卡了,只能在r7 8845的780m核显上面跑,然后我的恶梦开始了
首先自然是想到用rocm,但是rocm好像和隔壁的openvino不太一样,这玩意似乎只是提供了一个接口把计算扔到gpu上面,而我显然是不会自己解析rocm然后手动运算的,因此我得搞个框架来用
1.onnxruntime
问ai第一个给我蹦出来就这,巧的是我恰好装过了,那么就开整吧
onnxruntime文档里面使用C++的例子很少,不过刚好够用了,首先建一下环境
Ort::Env env;
env = Ort::Env { ORT_LOGGING_LEVEL_ERROR, "Default" };
Ort::SessionOptions so;
int device_id = 1;
Ort::ThrowOnError(OrtSessionOptionsAppendExecutionProvider_ROCM(so, device_id));
Ort::Session session(env, onnx_file.c_str(), session_options)
然后读进数据
Ort::MemoryInfo memory_info =
Ort::MemoryInfo::CreateCpu(OrtArenaAllocator, OrtMemTypeDefault);
int64_t shape[] = { 1, 384, 640, 3 }; //如果你觉得输入很奇怪是因为这是魔改yolo
Ort::Value input_tensor =
Ort::Value::CreateTensor<float>(memory_info,
input.ptr<float>(),
input.total() * sizeof(float),
shape,
4);
接下来推理
auto output_tensors = session.Run(Ort::RunOptions { nullptr },
input_names.data(),
&input_tensor,
1,
output_names.data(),
1);
auto output = std::move(output_tensors.front());
float* output_buffer = output.GetTensorMutableData<float>();
// 后处理
// ...
阿达西,amd老爷送我的钟怎么倒着转啊😧
如果就这么直接跑,你大概无法得到这种令人舒适的结果
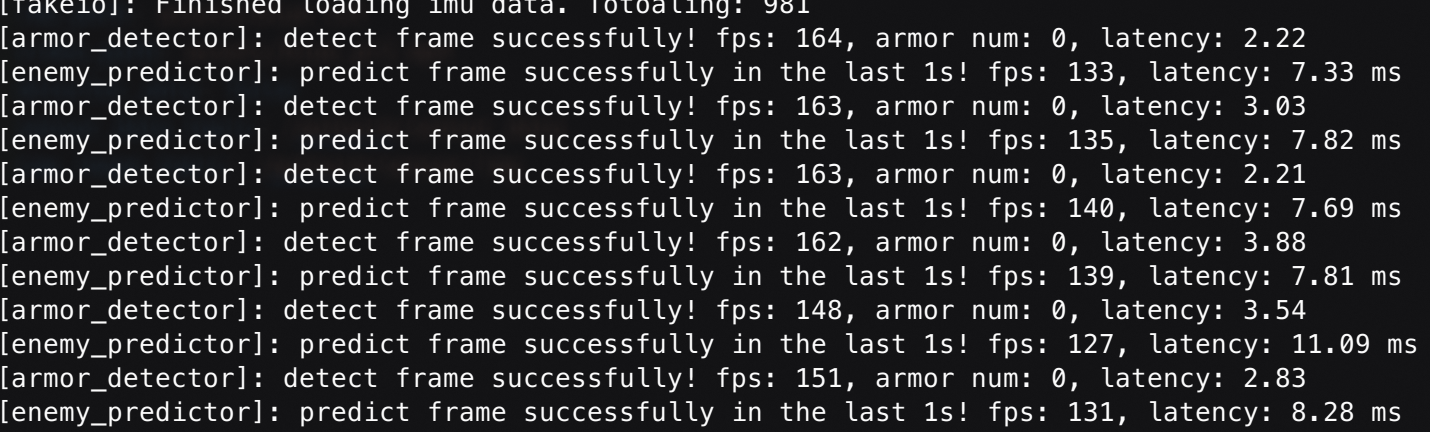
而是类似

这是为什么呢,因为巴依老爷心善(大嘘),根本没给igpu做适配🤓☝🏻
不过其实解决方法也很简单
780m核显的代号是gfx1103,而7900xtx的代号是gfx1100,很巧的是,gfx1100的配置是可以直接使用的
因此只需添加一行环境变量
export HSA_OVERRIDE_GFX_VERSION=11.0.0
然后你发现就可以跑了,教程结束!
然而,当你跑起来的时候,你可能会发现,似乎速度并不像你想象的那么快啊,甚至没cpu快
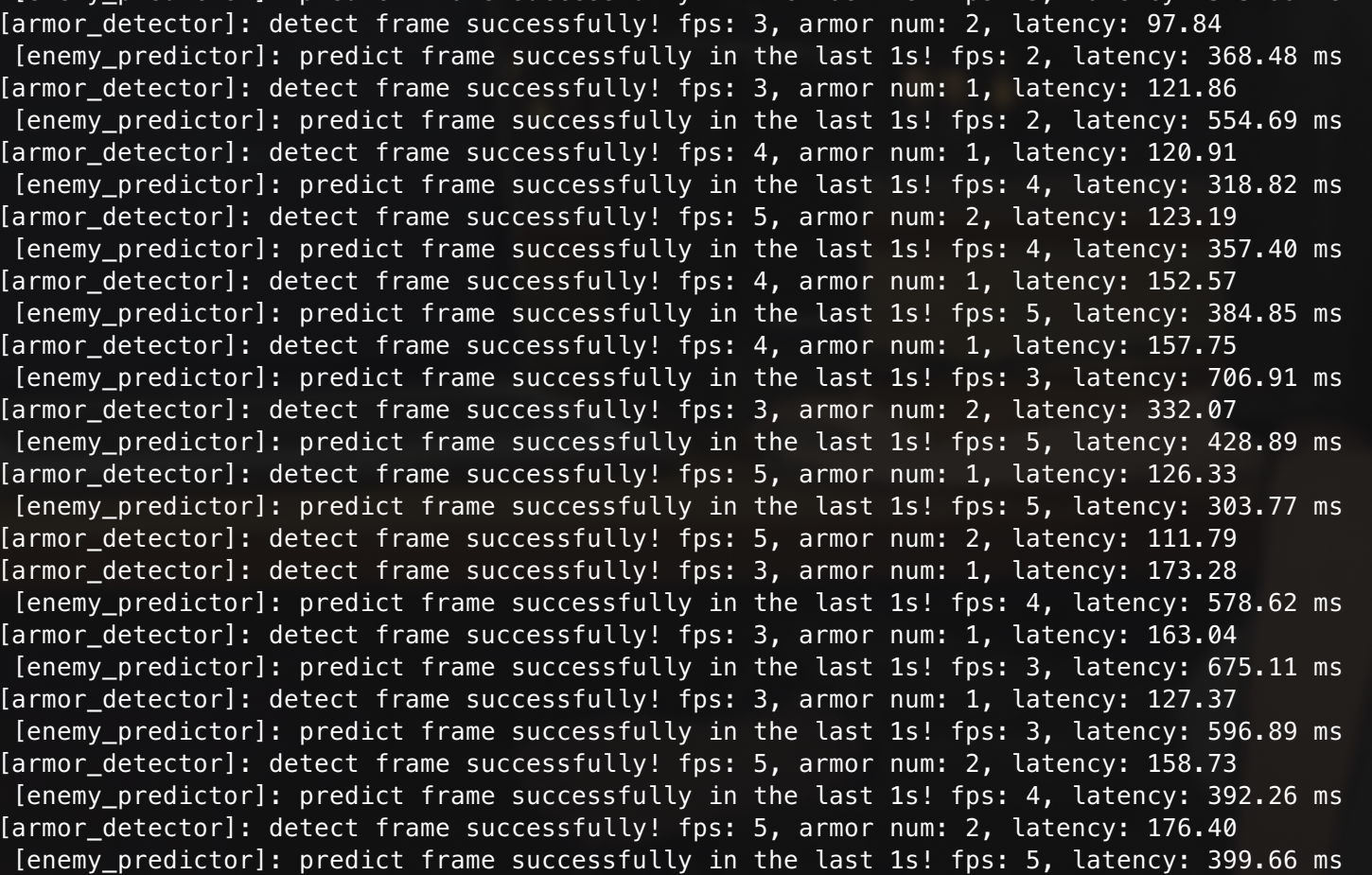
根据我的猜测,这可能是因为rocm并没有对dnn做任何优化,那么直接跑推理的性能就很搞笑了,看来rocm是不太行了,那么amd还有什么框架呢
2.migraphx
相关知识MIGraphX documentation
MIGraphX is a graph inference engine and graph compiler. MIGraphX accelerates machine-learning models by leveraging several graph-level transformations and optimizations. These optimizations include:
- Operator fusion
- Arithmetic simplifications
- Dead-code elimination
- Common subexpression elimination (CSE)
- Constant propagation
After optimization, MIGraphX generates code for AMD GPUs by calling various ROCm libraries to create the fastest combinations of HIP kernels.
Waiting for api.github.com...
综上所述,migraphx就是一个amd开发用来进行图像识别的优化库,看来用这个准没错了,然而,直接使用,你可能会得到
terminate called after throwing an instance of 'migraphx::version_2_10_0::exception'
what(): /long_pathname_so_that_rpms_can_package_the_debug_info/src/extlibs/AMDMIGraphX/src/targets/gpu/mlir.cpp:728: run_high_level_pipeline: Invalid MLIR created: Error: num_cu=30 : i64 cannot be lower than arch minNumCU=48
Note: see current operation: %7 = "tosa.conv2d"(%1, %2, %0) <{dilation = array<i64: 1, 1>, group = 1 : i64, pad = array<i64: 0, 0, 0, 0>, stride = array<i64: 1, 1>}> {filter_layout = "kcyx", input_layout = "nhcw", output_layout = "nhkw"} : (tensor<1x4x16x8400xf32>, tensor<1x16x1x1xf32>, tensor<1xf32>) -> tensor<1x4x1x8400xf32>
Error: Disjointed yx or hw!
Note: see current operation: %7 = "rock.conv"(%5, %4, %6) <{arch = "gfx1100", dilations = [1 : index, 1 : index], features = #rock<GemmFeatures dot|atomic_add|atomic_fmax_f32>, padding = [0 : index, 0 : index, 0 : index, 0 : index], strides = [1 : index, 1 : index]}> {filter_layout = ["g", "k", "c", "y", "x"], input_layout = ["ni", "hi", "gi", "ci", "wi"], output_layout = ["no", "ho", "go", "ko", "wo"]} : (tensor<1x1x16x1x1xf32>, tensor<1x4x1x16x8400xf32>, tensor<1x4x1x1x8400xf32>) -> tensor<1x4x1x1x8400xf32>
😕?
这是因为当前migraphx并不支持yolo v8(笑嘻了),其实社区已经有相关的pr了,但是还未经测试,如果你只跑yolo v8的话可以尝试合并进来然后自己编译
编译
如果你使用的是ubuntu或向我一样使用了opencl-amd-devAUR全家桶的话,我建议使用docker编译,因为如果你的migraphx和rocm使用的protobuf版本不同就会直接爆炸💥,我就是被这个玩意坑惨了😭,当然,如果是其他情况你可以自行处理。
拉取仓库
没什么好说的,记得cherrypick
git clone https://github.com/ROCm/AMDMIGraphX.git
git cherry-pick 5be961565482669bb9e5de86c08a678afcbe5a95
配置docker
docker build -t migraphx .
docker run --device='/dev/kfd' \
--device='/dev/dri' \
-v=`pwd`:/code/AMDMIGraphX \
-w /code/AMDMIGraphX \
--group-add video \
-it migraphx
编译
mkdir build
cd build
CXX=/opt/rocm/llvm/bin/clang++ \
cmake .. \
-DGPU_TARGETS=$(/opt/rocm/bin/rocminfo | grep -o -m1 'gfx.*') \
-DCMAKE_PREFIX_PATH=$your_loc
注意如果你稍后打包为deb,安装的目录默认是/opt/rocm,这和-DCMAKE_PREFIX_PATH配置并不相同,请自行设置CPACK_INSTALL_PREFIX,这对使用opencl-amd-devAUR全家桶的有帮助,因为其直接使用了amd的的deb包重新打包,且其包安装目录为/opt/rocm-$version/,若直接替换deb文件会导致文件结构出错
使用
总算结束准备工作了好累哦,要不明天再写代码
接下来是码代码时间
首先读取onnxfile并创建缓存便于下一次使用
std::filesystem::path onnx_path(onnx_file);
auto dir = onnx_path.parent_path();
auto base_name = onnx_path.stem().string();
auto onnx_cache = dir / (base_name + ".mxr");
migraphx::program prog;
if (std::filesystem::exists(onnx_cache)) {
prog = migraphx::load(onnx_cache.c_str());
} else {
migraphx::onnx_options onnx_opts;
prog = migraphx::parse_onnx(onnx_file.c_str(), onnx_opts);
migraphx::target targ = migraphx::target("gpu");
migraphx::compile_options comp_opts;
comp_opts.set_offload_copy();
comp_opts.set_fast_math();
migraphx::quantize_fp16(prog);
prog.compile(targ, comp_opts);
try {
migraphx::save(prog, onnx_cache.c_str());
} catch (const std::exception& e) {
std::cout<<"Error: "<<e<<std::endl
}
}
然后进行推理
migraphx::program_parameters prog_params;
auto param_shapes = prog.get_parameter_shapes();
auto input = param_shapes.names().front();
prog_params.add(input, migraphx::argument(param_shapes[input], blob_permuted.data));
auto outputs = prog.eval(prog_params);
float* output_buffer = (float*)outputs[0].data();
// 后处理
// ...
结果
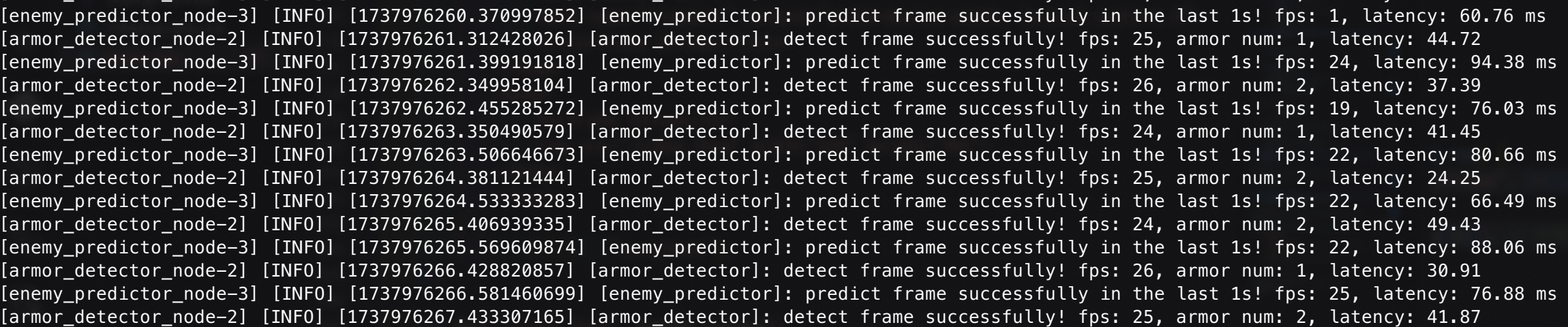
其实也没多快
番外
其实在使用时你还会碰上一个神秘的问题,具体来说是突然眼前屏幕一黑,恢复后推理中断,只留下命令行的一行报错
HW Exception by GPU node-1 (Agent handle: 0x5ab48bbcc960) reason :GPU Hang
这是amdgpu的固件错误,你可以使用一个patch来阻止它干掉你的iGPU,但是可能会造成别的后果,酌情使用